
Vincent Schellekens
researcher in sustainable AI
My research focuses on different aspects of a framework called "Compressive Learning" (aka "Sketched Learning").
What is Compressive Learning?
Limitations of usual Machine Learning
In Machine Learning (ML), a mathematical model (such as a prediction rule) is not hand-crafted by a human expert but automatically discovered from a large set of learning examples (Fig. 1). In recent years, ML has had tremenduous success (amongst others, in the field of Artificial Intelligence); this is possible thanks to the improvement of ML methods, but also thanks to the ever-increasing abundance of data to learn from.
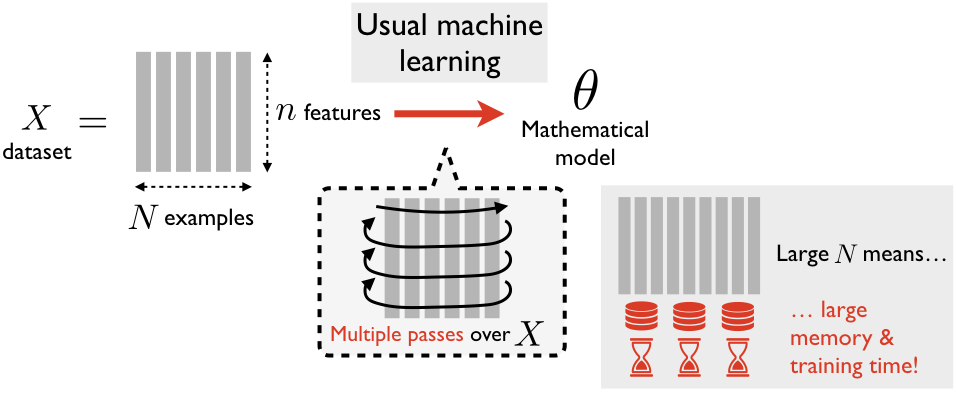
Usually, machine learning methods need access to the data multiple times during training. This becomes problematic when the dataset is very large (which is the case for modern datasets): a large memory is required to store all this data, and reading it repeatedly takes a lot of time.
Compressive Learning
One attempt to solve this problem is Compressive Learning, a framework introduced by Rémi Gribonval, Nicolas Keriven and co-authors (more). The idea is to break down expensive learning into two cheaper steps: sketching and the actual "learning" (Fig. 2).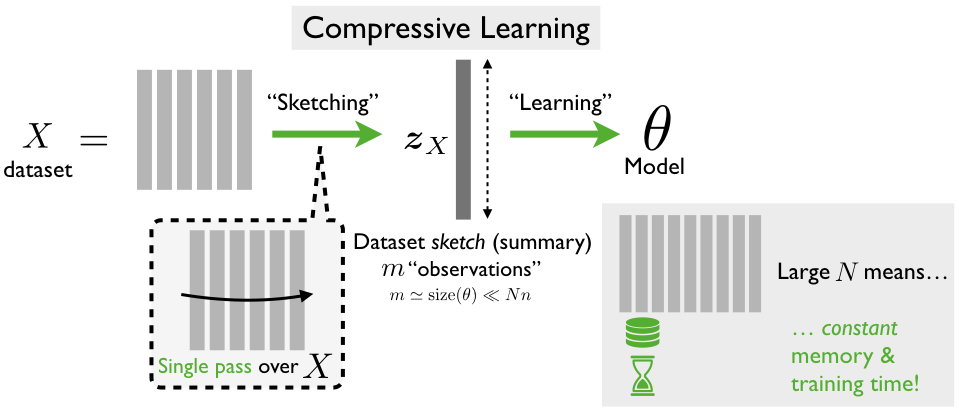
- Sketching amounts to compressing the dataset as a whole instead of element-by-element (more precisely, by computing a set of randomly generated generalized moments of the data). This summary of the dataset is called the sketch, and by construction its size does not grow with the number of examples in the dataset. In addition, the sketch is light to compute (can be done in parallel, on-line, on decentralized machines,...) and allows to delete the data after only looking at it only once.
- Learning amounts to extracting the target mathematical model, from the sketch only (thus requiring less computational resources than usual learning). This step involves solving an inverse problem, inspired from usual Compressed Sensing.
What problems do I focus on?
Here are some questions about Compressive Learning that I try to answer in my PhD research:
- Is it possible to make the sketching step more efficient? Ideally, is it possible to design a hardware system that computes the sketch contribution of a signal without aquiring it at all? In particular, in a practical digital system we need to quantize the sketch: how does this impact the learning performances?
- Can Compressive Learning be extended to new learning tasks (up to now, only K-Means and GMM estimation have been explored), to do for example classification or regression? Can Compressive Learnign be used on more complex but structured data than current applications?
- Can we obtain formal guarantees on the practical algorithms used in the learning step? Can the existing algorithms be made more efficient?
- Is it possible to use the sketch mechanism to provide some privacy guarantees for the users contributing to the database?
- ...